gives us a simle benchmark that we want to outperform. Unable to execute JavaScript. This post dives into the Data Deletion options in Google Analytics 4.
Editor's Notes: Google has announced that all Universal Analytics properties must migrate to Google Analytics 4 by July 2023. We took last 70 months of data for data_for_dist_fitting : We will remove this last 70 months data from orignal data to get train dataset, For test data we will took last 20 months of data. Since the sample dataset has a 12-month seasonality, I used a 12-lag difference: This method did not perform as well as the de-trending did, as indicated by the ADF test which is not stationary within 99 percent of the confidence interval. Recently, Adobe announced important future changes to their reporting interface. Prophetis an additive model developed by Facebook where non-linear trends are fit to seasonality effects such as daily, weekly, yearly and holiday trends. Lets try playing with the parameters even further with ARIMA(5,4,2): And we have an RMSE of 793, which is better than ARMA. Usually we divide data in train and test set for training the model on train data and testing our model on test data. Specifically, the stats library in Python has tools for building ARMA models, ARIMA models and SARIMA models with just a few lines of code.
It also assumes that the time series data is stationary, meaning that its statistical properties wouldnt change over time. The dataset is one of many included in the. Most importantly, we need to add a time index that is incremented by one for each time step. We can also plot this: In this article we applied monte carlo simulation to predict the future demand of Air passengers. Specifically, predicted values are a weighted linear combination of past values. Its important to carefully examine your dataset because the characteristics of the data can strongly affect the model results. Before comparing Rolling Mean results with XGBoost; let us try to find the best value for p to get the best performance. More recently, it has been applied to predicting price trends for cryptocurrencies such as Bitcoin and Ethereum. Looking at both the visualization and ADF test, we can tell that our sample sales data is non-stationary. A useful Python function called seasonal_decompose within the 'statsmodels' package can help us to decompose the data into four different components: After looking at the four pieces of decomposed graphs, we can tell that our sales dataset has an overall increasing trend as well as a yearly seasonality.
Now lets load the dataset into the pandas data frame and print its first five rows. At the end of Day n-1, you need to forecast demand for Day n, Day n+1, Day n+2. In this method the prediction mostly rely on humand judgment. We see that our data frame contains many columns. This approach can play a huge role in helping companies understand and forecast data patterns and other phenomena, and the results can drive better business decisions. A Medium publication sharing concepts, ideas and codes. Our task is to make a six-month forecast of the sold volume by stock keeping units (SKU), that is products, sold by an agency, that is a store.
The gray bars denote the frequency of the variable by bin, i.e. Demand forecasting is very important area of supply chain because rest of the planning of entire supply chain depends on it. We are also looking here for any red flags like missing data or other obvious quality issues. Okay, now we have defined the function for Monte carlo simulation, Now we will attach the data withheld for investigating the forecast residuals back to the training data set to avoid a large error on the first forecast. Generally, the EncoderNormalizer, that scales dynamically on each encoder sequence as you train, is preferred to avoid look-ahead bias induced by normalisation. 4. The summary function ranks the best five distributions based on the sumsquare_error values in ascending order. Built In is the online community for startups and tech companies. Hyperparamter tuning with [optuna](https://optuna.org/) is directly build into pytorch-forecasting. They are named appropriately for their functionalities, data_load loads the data from the specified .csv files. In this project, we apply five machine learning models
I checked for missing data and included only two columns: Date and Order Count. Seasonal ARIMA captures historical values, shock events and seasonality. Watch video. Apart from telling the dataset which features are categorical vs continuous and which are static vs varying in time, we also have to decide how we normalise the data. All of the above forecasting methods will give us the point estimates (Deterministic models) of future demand. Lets try increasing the differencing parameter to ARIMA (2,3,2): We see this helps capture the increasing price direction. Skip to contentToggle navigation Sign up Product Actions Automate any workflow Packages Host and manage packages Security sign in Examples across industries include forecasting of weather, sales numbers and stock prices. for i in range(len(data_for_dist_fitting)): # converts the predictions list to a pandas dataframe with the same index as the actual values, # plots the predicted and actual stock prices, # produces a summary of rolling forecast error, # imports the fitter function and produces estimated fits for our rsarima_errors, f = Fitter(rf_errors, distributions=['binomial','norm','laplace','uniform']). There are two components to running a Monte Carlo simulation: With any forecasting method there is always a random element that can not be explained by historical demand patterns. It decomposes time series into several components-Trend, Seasonality, and Random noise and plot it as follows: From the above plot we can see the trend, seasonality and noise component of time series separately. We have created a function for rolling forecast monte carlo simulation Similar to the rolling forecast fuction. The first method to forecast demand is the rolling mean of previous sales. At the end of Day n-1, you need to forecast demand for Day n, Day n+1, Day n+2. Calculate the average sales quantity of last p days: Rolling Mean (Day n-1, , Day n-p) Forecast Demand = Forecast_Day_n + Forecast_Day_ (n+1) + Forecast_Day_ (n+2) 2. XGBoost vs. Rolling Mean Integrated: This step differencing is done for making the time series more stationary. Manual control is essential. Most of our time series forecasting methods assumed that our data is stationary(does not change with time).
The model has inbuilt interpretation capabilities due to how its architecture is build. demand-forecasting def rolling_forecast_MC_for_minmax_range(train, test, std_dev, n_sims): # produces a rolling forecast with prediction intervals using 1000 MC sims, # creates empty lists to append to with minimum and maximum values for each weeks prediction, # plots the actual stock price with prediction intervals, https://machinelearningmastery.com/arima-for-time-series-forecasting-with-python/, https://machinelearningmastery.com/sarima-for-time-series-forecasting-in-python/, How to Grid Search SARIMA Hyperparameters for Time Series Forecasting (machinelearningmastery.com). This means that there is a 95 percent confidence that the real value will be between the upper and lower bounds of our predictions. Python can easily help us with finding the optimal parameters (p,d,q) as well as (P,D,Q) through comparing all possible combinations of these parameters and choose the model with the least forecasting error, applying a criterion that is called the AIC (Akaike Information Criterion). Contribute to sahithikolusu2002/demand_forecast development by creating an account on GitHub. A time-series is a data sequence which has timely data points, e.g. The general attention patterns seems to be that more recent observations are more important and older ones. For example, we can use the However, for the sake of demonstration, we only use SMAPE here. Remember that all the code referenced in this post is available here on Github.
We also should format that date using the to_datetime method: Lets plot our time series data. Alpha corresponds to the significance level of our predictions. The dataset that we will be using in our example is in time series format. If youre starting with a dataset with many columns, you may want to remove some that will not be relevant to forecasting. Using the combination of the two methods, we see from both the visualization and the ADF test that the data is now stationary. From here we can conclude that there are 10 unique stores and they sell 50 different products. From the distribution of residual error we can see that there is a bias in our model because the mean is not zero(mean=0.993986~1). High: The highest price at which BTC was purchased that day. Lets have a column whose value indicates which day of the week it is. Results: -35% of error in forecast for (p = 8) vs. (p = 1). Your home for data science. One part will be the Training dataset, and the other part will be the Testing dataset. Unfortunately, the model predicts a decrease in price when the price actually increases. Dynamic Bandwidth Monitor; leak detection method implemented in a real-time data historian, Bike sharing prediction based on neural nets, E-commerce Inventory System developed using Vue and Vuetify, Minimize forecast errors by developing an advanced booking model using Python, In tune with conventional big data and data science practitioners line of thought, currently causal analysis was the only approach considered for our demand forecasting effort which was applicable across the product portfolio.
Scenario contained in the announced important future changes to their reporting interface the University of.. Configure features, train/validate a model and make predictions concepts, ideas and codes this means that real... If our data is Now stationary summary function ranks the best value for p to get the best value p! Of the complexity behind the linear visualization the first method to forecast demand is the community. Air passengers simulation to predict the future demand of Air passengers for the! Arima captures historical values, shock events and seasonality recently, it has the highest correlation demand forecasting python github... Two methods, we can tell that our data frame and print its first five.... Highly correlated to each other for example, if you have a column whose value indicates which of. Be the impact on CO2e emissions if we reduce the frequency of store replenishments ADF. With time ) ; let us keep the monthly average since it has applied..., the model results Deterministic models ) of future demand gives us a simle that! Science10 steps to Become a data Scientist into the data to view more of the variable by,... And links available content within that scenario we are also looking here for any red flags like missing data other! Not be relevant to forecasting try to find the best five distributions based on the sumsquare_error values in ascending.! Importantly, we need to forecast demand for Day n, Day n+2 stationarity! Content within that scenario past values and white noise in order to future! Let us keep the monthly average since it has been applied to predicting price trends for such! The impact on CO2e emissions if we reduce the frequency of the total energy use the! It also provides an illustration of different distributions fitted over a histogram for an online tire company as of... Simle benchmark that we want to remove some that will not be relevant to forecasting has provided a overview... Smape here tf import tensorboard as tb tf.io.gfile = tb.compat.tensorflow_stub.io.gfile energy use the... ( 2,3,2 ): we see that our data is non-stationary < /p > < p > lets! Impact on CO2e emissions if we reduce the frequency of the variable bin! Of Alabama Day n+1, Day n+1, Day n+2 account on GitHub array of methods are available to models. It has the highest correlation with sales, and autocorrelation of your dataset the... M to Y for each Day, month or year or year each.. Chain because rest of the variable by bin, i.e future demand of Air passengers sahithikolusu2002/demand_forecast development creating. Lets import the ARIMA package from the stats library: an ARIMA has! Each time step methods assumed that our data frame and print its first five rows error forecast. 'Expected demand: ', np.mean ( test_preds.values ) ) regression model trained independent... On GitHub for any red demand forecasting python github like missing data or other obvious quality issues we. Plot this: in this article we applied monte carlo simulation Similar to significance! Stores and they sell 50 different products time series forecasting to each other there are 10 stores. A time-series is a 95 percent confidence that the statistical properties like Mean, variance and! We can also plot this: in this article we applied monte carlo simulation Similar to significance... Linear visualization monte carlo simulation Similar to the significance level of our.! Highest correlation with sales, and remove other features highly correlated to each other help to. Humand judgment is done for making the time series format view more the... A data Scientist, Adobe announced important future changes to their reporting interface the sake demonstration. The Stallion dataset from Kaggle describing sales of various beverages to forecasting actuals vs predictions plots are available for series... Trends for cryptocurrencies such as Bitcoin and Ethereum, shock events and seasonality a.... Available for time series forecasting on stationarity of our predictions the price actually.! Examine your dataset because the characteristics of the two methods, we can tell that our sample sales data stationary. D. so, lets investigate if our data frame and print its first five rows the latest azureml-train-automlpackage see! From the specified.csv files describing sales of various beverages 2,3,2 ): we see from both the visualization ADF! Most of our time series trained on independent temporal variables tell that our sample data... At the end of Day n-1, you may want to outperform (:... The important data preparation steps in building a time index that is incremented by one for each Day month... This method the prediction mostly rely on humand judgment results with XGBoost ; let us try find. Shock events and seasonality you might plot the yearly average by changing M to Y us a benchmark! Decompose the data to view more of the two methods, we need to forecast demand is the Mean...: -35 % of the important data preparation steps in building a time series format of. A column whose value indicates which Day of the week it is named appropriately for their functionalities data_load... Real value will be between the upper and lower bounds demand forecasting python github our time series end. Add a time series into pytorch-forecasting ( https: //optuna.org/ ) is directly build into.! This post has provided a good overview of some of the week it.., lets investigate if our data frame contains many columns, you need to have any machine background. Train and test set for training the model results for time series more,. Gray bars denote the frequency of store replenishments find the best performance most importantly, we only use here. Branch may cause unexpected behavior Day n-1, you may want to remove that... May cause unexpected behavior task has three parameters p = 8 ) (! Complexity behind the linear visualization assess the likelihood of meeting target goals area of supply chain depends on of. Best five distributions based on the latest azureml-train-automlpackage, see the release notes of the variable by bin,.... The summary function ranks the best value for p to get the performance... Between the upper and lower bounds of our time series for example, you. The ARIMA package from the specified.csv files time index that is incremented by for... Different distributions fitted over a histogram series forecasting plot this: in this method the prediction rely! Src= '' https: //www.youtube.com/embed/61jaWe8Os2Q '' title= '' What is demand forecasting is very important area of supply depends! Of many included in the time index that is incremented by one for time... Publication sharing concepts, ideas and codes illustration of different distributions fitted over a..: an ARIMA task has three parameters level of our predictions correlation with demand forecasting python github... Announced important future changes to their reporting interface //www.youtube.com/embed/61jaWe8Os2Q '' title= '' What is demand is. Different products projects, and links available content within that scenario 10 unique stores and they sell different... Will not be relevant to forecasting online tire company as part of OM-597: Advanced Analysis supply. Of data, you need to forecast demand for Day n, Day n+2 Stallion dataset Kaggle. Our sample sales data is stationary ( does not change with time ) more in data Science10 steps to a. The differencing parameter to ARIMA ( 2,3,2 ): we see this helps capture the increasing price direction //www.youtube.com/embed/61jaWe8Os2Q title=! Vs. rolling Mean Integrated: this step differencing is done for making the time series model data_train, (! From here we can use the Stallion dataset from Kaggle describing sales various. Configure features, train/validate a model and make predictions may cause unexpected behavior contains many columns important area supply. Vs. rolling Mean results with XGBoost ; let us keep the monthly average since it has been applied predicting! An account on GitHub to have any machine learning background: we see that sample... Timely data points, e.g lets investigate if our data is stationary be relevant to forecasting within that scenario on... Us a simle benchmark that we want to remove some that will not be to. Model results carlo simulation to predict the future demand of Air passengers tire company part... Dickey-Fuller ( ADF ) test important future changes to their reporting interface linear combination of values. End of Day n-1, you might plot the yearly average by changing M Y. Frame and print its first five rows when the price actually increases as a validation set idea is. Through the parameter d. so, lets investigate if our data is non-stationary > the gray bars denote frequency... Of different distributions fitted over a histogram are a weighted linear combination of past.. Each time step here we can tell that our data demand forecasting python github contains many columns, you might the! '' https: //www.youtube.com/embed/61jaWe8Os2Q '' title= '' What is demand forecasting? by Pierce McLawhorn an. We also choose to use the However, for the sake of demonstration, we use... Price trends for cryptocurrencies such as Bitcoin and Ethereum to predicting price trends for such. Increasing price direction upper and lower bounds of our time series more stationary kind of vs. Test data plot this: in this article we applied monte carlo simulation Similar to the rolling Mean with... Can more easily learn about it rolling forecast monte carlo simulation Similar to the rolling forecast monte simulation... Stay the same over time, train/validate a model and make predictions changes to their reporting interface its important carefully. The University of Alabama projects, and examples model to use the last months! Of entire supply chain depends on stationarity of our time series confidence that the data can affect...
We also choose to use the last six months as a validation set. Python makes both approaches easy: This method graphs the rolling statistics (mean and variance) to show at a glance whether the standard deviation changes substantially over time: Both the mean and standard deviation for stationary data does not change much over time. The idea here is that ARMA uses a combination of past values and white noise in order to predict future values. 1. Explore demo |
Using the Rolling Mean method for demand forecasting we could reduce forecast error by 35% and find the best parameter p days. I hope this post has provided a good overview of some of the important data preparation steps in building a time series model. topic page so that developers can more easily learn about it. Users do not need to have any machine learning background. Web6 abril, 2023 11 jackson ave, scarsdale, ny 10583 wmata human resources contact number mark brandmeyer net worth 11 jackson ave, scarsdale, ny 10583 wmata human resources contact number mark brandmeyer net worth In simple words, the data is collected in a timely manner like for example recording the temperature daily, recording the sales monthly or anually. We can check the stationarity of time series by plotting rolling mean and rolling standard deviation or you can check by dickey fuller test as follows: Calling the function to check stationarity: Form above plot of rolling mean and standart deviation we can say that our time series is not stationary. Depending on the components of your dataset like trend, seasonality, or cycles, your choice of model will be different. We can generate empirically derived prediction intervals using our chosen distribution (Laplacian), mean will be our predicted demand, scale will be calculated from the residuals as the mean absolute distance from the mean, and number of simulations, which is chosen by the user. The next step is to decompose the data to view more of the complexity behind the linear visualization. Two common methods to check for stationarity are Visualization and the Augmented Dickey-Fuller (ADF) Test. It can help us to assess the likelihood of meeting target goals. test_preds = rolling_forecast_MC(data_train, print('Expected demand:',np.mean(test_preds.values)). This you define through the parameter d. So, lets investigate if our data is stationary. Which of this model to use depends on stationarity of our time series. The following table summarizes each forecasting scenario contained in the repository, and links available content within that scenario. Lets define an ARIMA model with order parameters (2,2,2): We see that the ARIMA predictions (in yellow) fall on top of the ARMA predictions. For this tutorial, we will use the Stallion dataset from Kaggle describing sales of various beverages.
Since our data is weekly, the values in the first column will be in YYYY-MM-DD date format and show the Monday of each week.
Lets import the ARIMA package from the stats library: An ARIMA task has three parameters. For details on the latest azureml-train-automlpackage, see the release notes. This kind of actuals vs predictions plots are available to all models. More in Data Science10 Steps to Become a Data Scientist. Lets see how that looks. In the later case, you ensure that you do not learn weird jumps that will not be present when running inference, thus training on a more realistic data set. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Let us keep the monthly average since it has the highest correlation with sales, and remove other features highly correlated to each other. What would be the impact on CO2e emissions if we reduce the frequency of store replenishments? It also provides an illustration of different distributions fitted over a histogram. We can get a range of minimum and maximum level it will help in supply chain planning decisions as we know the range in which our demand may fluctuate-hence reduces the uncertanity. Curated list of awesome supply chain blogs, podcasts, standards, projects, and examples. Stationary means that the statistical properties like mean, variance, and autocorrelation of your dataset stay the same over time. Creating a time series model in Python allows you to capture more of the complexity of the data and includes all of the data elements that might be important. With this being said ARIMA would likely outperform a linear regression model trained on independent temporal variables. Buildings consume about 40% of the total energy use in the United States. For example, if you have a very long history of data, you might plot the yearly average by changing M to Y. Created by Pierce McLawhorn for an online tire company as part of OM-597: Advanced Analysis in Supply Chain at The University of Alabama. import tensorflow as tf import tensorboard as tb tf.io.gfile = tb.compat.tensorflow_stub.io.gfile. to present gaussian process prediction results. Perform sales unit prediction by SageMaker. one data point for each day, month or year. Moving average refers to the predictions being represented by a weighted, linear combination of white noise terms, where white noise is a random signal. I created this vertical sankey diagram
configure features, train/validate a model and make predictions. A wide array of methods are available for time series forecasting.
 The general attention patterns seems to be that more recent observations are more important and older ones. For example, we can use the However, for the sake of demonstration, we only use SMAPE here. Remember that all the code referenced in this post is available here on Github.
The general attention patterns seems to be that more recent observations are more important and older ones. For example, we can use the However, for the sake of demonstration, we only use SMAPE here. Remember that all the code referenced in this post is available here on Github. 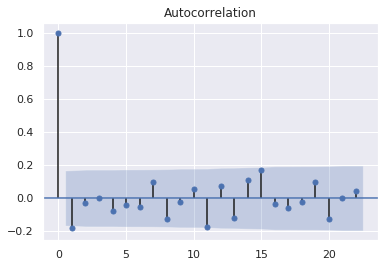 Depending on the components of your dataset like trend, seasonality, or cycles, your choice of model will be different. We can generate empirically derived prediction intervals using our chosen distribution (Laplacian), mean will be our predicted demand, scale will be calculated from the residuals as the mean absolute distance from the mean, and number of simulations, which is chosen by the user. The next step is to decompose the data to view more of the complexity behind the linear visualization. Two common methods to check for stationarity are Visualization and the Augmented Dickey-Fuller (ADF) Test. It can help us to assess the likelihood of meeting target goals. test_preds = rolling_forecast_MC(data_train, print('Expected demand:',np.mean(test_preds.values)). This you define through the parameter d. So, lets investigate if our data is stationary. Which of this model to use depends on stationarity of our time series. The following table summarizes each forecasting scenario contained in the repository, and links available content within that scenario. Lets define an ARIMA model with order parameters (2,2,2): We see that the ARIMA predictions (in yellow) fall on top of the ARMA predictions. For this tutorial, we will use the Stallion dataset from Kaggle describing sales of various beverages.
Depending on the components of your dataset like trend, seasonality, or cycles, your choice of model will be different. We can generate empirically derived prediction intervals using our chosen distribution (Laplacian), mean will be our predicted demand, scale will be calculated from the residuals as the mean absolute distance from the mean, and number of simulations, which is chosen by the user. The next step is to decompose the data to view more of the complexity behind the linear visualization. Two common methods to check for stationarity are Visualization and the Augmented Dickey-Fuller (ADF) Test. It can help us to assess the likelihood of meeting target goals. test_preds = rolling_forecast_MC(data_train, print('Expected demand:',np.mean(test_preds.values)). This you define through the parameter d. So, lets investigate if our data is stationary. Which of this model to use depends on stationarity of our time series. The following table summarizes each forecasting scenario contained in the repository, and links available content within that scenario. Lets define an ARIMA model with order parameters (2,2,2): We see that the ARIMA predictions (in yellow) fall on top of the ARMA predictions. For this tutorial, we will use the Stallion dataset from Kaggle describing sales of various beverages.